소개
VGG16은 16개 층으로 이루어진 VGGNet을 의미합니다.
VGGNet(VGG19)는 2014년도 ILSVRC(ImageNet Large Sclae Visual Recognition Challenge)에서 준우승한 CNN 네크워크입니다.
VGGNet(VGG19)는 사용하기 쉬운 구조와 좋은 성능 덕분에 그 대회에서 우승을 거둔 조금 더 복잡한 형태의 GoogLeNet보다 더 인기를 얻었습니다.
VGGNet의 논문 이름은 "Very deep convolutional networks for large-scale image recognition"로, 네트워크의 깊이를 깊게 만드는 것이 성능에 어떤 영향을 미치는지 확인하는 목적을 가집니다.
특징

VGGNet 연구팀은 깊이의 영향만을 최대한 확인하고자 Convolution 횟수에 따라 6개의 구조로 나누어 성능을 비교합니다. 결과적으로, Network의 깊이가 깊어질수록 객체 인식 에러가 감소하는 것을 확인합니다.
3 x 3 Filter

- 3 x 3 필터로 2번 Convolution하는 것과 5 x 5 필터로 1번 Convolution 하는 것은 동일한 사이즈의 Feature Map을 나타냅니다.
- VGGNet에서 3 x 3 필터를 사용한 이유는, 3 x 3 필터 3개는 총 27개의 가중치를 갖고 7 x 7 필터는 총 49개의 가중치를 갖기 때문입니다. 가중치가 적다는 것은 훈련시켜야할 대상의 갯수가 적어진다는 뜻으로 학습속도에 영향을 미칩니다.
A와 A-LRN
- VGG 연구팀은 Local Response Normalization을 활용한 A-LRN 구조와 그렇지 않은 A 구조를 비교하였을 때 성능 향상에 효과가 없음을 확인합니다.
- 따라서 이후 실험하는 B, C, D, E 구조에는 Local Response Normalization을 적용하지 않습니다.
VGG16 구조
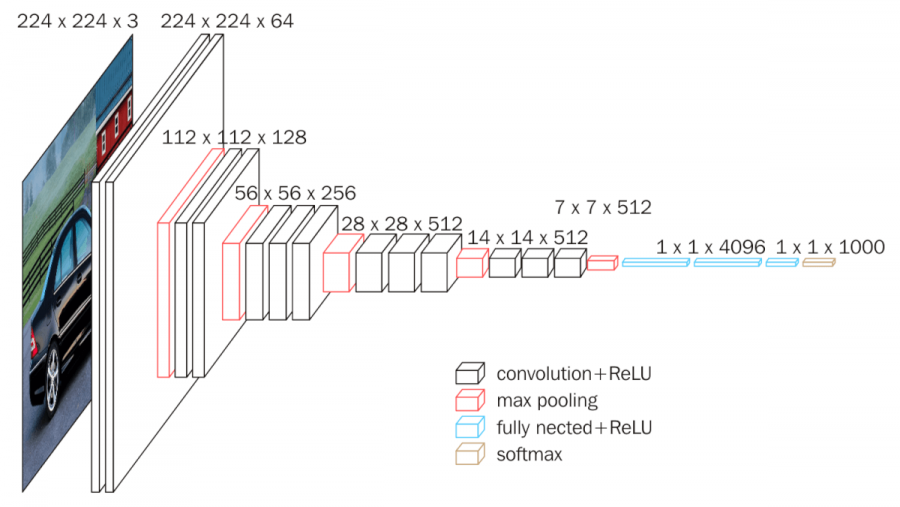
VGG16은 13개의 Convolution Layer와 3개의 Fully Connected Layer로 구성되어 있습니다.
Input Image
- 224 x 224 x 3 이미지를 입력으로 받습니다.
First Layer(Convolution Layer)
- 64개의 3 x 3 x 3 필터 커널로 입력 이미지를 Convolution 해줍니다. 보폭(stride)과 Zero Padding 모두 1로 설정해주면 Output으로 224 x 224 x 64 Feature Map을 얻게됩니다.
- 활성화 함수로 ReLU 함수를 사용합니다.
Second Layer(Convolution Layer)
- 64개의 3 x 3 x 64 필터 커널로 이전 단계의 Feature Map을 Convolution 해줍니다. 보폭(stride)과 Zero Padding 모두 1로 설정해주면 Output으로 224 x 224 x 64 Feature Map을 얻게됩니다.
- 활성화 함수로 ReLU 함수를 사용합니다.
- 그리고 2 x 2 Max Pooling을 보폭(stride) 2로 설정하면 112 x 112 x 64의 Feature Map이 나옵니다.
- Max Pooling이 진행되기 전인 First Layer와 Second Layer를 합쳐서 하나의 모듈로 생각할 수 있습니다.
Third Layer(Convolution Layer)
- 128개의 3 x 3 x 64 필터 커널로 이전 단계의 Feature Map을 Convolution 해줍니다. 보폭(stride)과 Zero Padding 모두 1로 설정해주면 Output으로 112 x 112 x 128 Feature Map을 얻게됩니다.
- 활성화 함수로 ReLU 함수를 사용합니다.
Fourth Layer(Convolution Layer)
- 128개의 3 x 3 x 128 필터 커널로 이전 단계의 Feature Map을 Convolution 해줍니다. 보폭(stride)과 Zero Padding 모두 1로 설정해주면 Output으로 112 x 112 x 128 Feature Map을 얻게됩니다.
- 활성화 함수로 ReLU 함수를 사용합니다.
- 그리고 2 x 2 Max Pooling을 보폭(stride) 2로 설정하면 56 x 56 x 128의 Feature Map이 나옵니다.
- Max Pooling이 진행되기 전인 Third Layer와 Fourth Layer를 합쳐서 하나의 모듈로 생각할 수 있습니다.
Fifth Layer(Convolution Layer)
- 256개의 3 x 3 x 128 필터 커널로 이전 단계의 Feature Map을 Convolution 해줍니다. 보폭(stride)과 Zero Padding 모두 1로 설정해주면 Output으로 56 x 56 x 256 Feature Map을 얻게됩니다.
- 활성화 함수로 ReLU 함수를 사용합니다.
Sixth Layer(Convolution Layer)
- 256개의 3 x 3 x 256 필터 커널로 이전 단계의 Feature Map을 Convolution 해줍니다. 보폭(stride)과 Zero Padding 모두 1로 설정해주면 Output으로 56 x 56 x 256 Feature Map을 얻게됩니다.
- 활성화 함수로 ReLU 함수를 사용합니다.
Seventh Layer(Convolution Layer)
- 256개의 3 x 3 x 256 필터 커널로 이전 단계의 Feature Map을 Convolution 해줍니다. 보폭(stride)과 Zero Padding 모두 1로 설정해주면 Output으로 56 x 56 x 256 Feature Map을 얻게됩니다.
- 활성화 함수로 ReLU 함수를 사용합니다.
- 그리고 2 x 2 Max Pooling을 보폭(stride) 2로 설정하면 28 x 28 x 256의 Feature Map이 나옵니다.
- Max Pooling이 진행되기 전인 Fifth Layer와 Sixth Layer, Seventh Layer를 합쳐서 하나의 모듈로 생각할 수 있습니다.
Eighth Layer(Convolution Layer)
- 512개의 3 x 3 x 256 필터 커널로 이전 단계의 Feature Map을 Convolution 해줍니다. 보폭(stride)과 Zero Padding 모두 1로 설정해주면 Output으로 28 x 28 x 512 Feature Map을 얻게됩니다.
- 활성화 함수로 ReLU 함수를 사용합니다.
Ninth Layer(Convolution Layer)
- 512개의 3 x 3 x 512 필터 커널로 이전 단계의 Feature Map을 Convolution 해줍니다. 보폭(stride)과 Zero Padding 모두 1로 설정해주면 Output으로 28 x 28 x 512 Feature Map을 얻게됩니다.
- 활성화 함수로 ReLU 함수를 사용합니다.
Tenth Layer(Convolution Layer)
- 512개의 3 x 3 x 512 필터 커널로 이전 단계의 Feature Map을 Convolution 해줍니다. 보폭(stride)과 Zero Padding 모두 1로 설정해주면 Output으로 28 x 28 x 512 Feature Map을 얻게됩니다.
- 활성화 함수로 ReLU 함수를 사용합니다.
- 그리고 2 x 2 Max Pooling을 보폭(stride) 2로 설정하면 14 x 14 x 512의 Feature Map이 나옵니다.
- Max Pooling이 진행되기 전인 Eighth Layer와 Ninth Layer, Tenth Layer를 합쳐서 하나의 모듈로 생각할 수 있습니다.
Eleventh Layer(Convolution Layer)
- 512개의 3 x 3 x 512 필터 커널로 이전 단계의 Feature Map을 Convolution 해줍니다. 보폭(stride)과 Zero Padding 모두 1로 설정해주면 Output으로 14 x 14 x 512 Feature Map을 얻게됩니다.
- 활성화 함수로 ReLU 함수를 사용합니다.
Twelfth Layer(Convolution Layer)
- 512개의 3 x 3 x 512 필터 커널로 이전 단계의 Feature Map을 Convolution 해줍니다. 보폭(stride)과 Zero Padding 모두 1로 설정해주면 Output으로 14 x 14 x 512 Feature Map을 얻게됩니다.
- 활성화 함수로 ReLU 함수를 사용합니다.
Thirteenth Layer(Convolution Layer)
- 512개의 3 x 3 x 512 필터 커널로 이전 단계의 Feature Map을 Convolution 해줍니다. 보폭(stride)과 Zero Padding 모두 1로 설정해주면 Output으로 14 x 14 x 512 Feature Map을 얻게됩니다.
- 활성화 함수로 ReLU 함수를 사용합니다.
- 그리고 2 x 2 Max Pooling을 보폭(stride) 2로 설정하면 7 x 7 x 512의 Feature Map이 나옵니다.
- Max Pooling이 진행되기 전인 Eleventh Layer와 Twelfth Layer, Thirteenth Layer를 합쳐서 하나의 모듈로 생각할 수 있습니다.
Fourteenth Layer(Fully Connected Layer)
- 7 x 7 x 512 Feature Map을 flatten해주어 7 x 7 x 512 = 25088차원의 벡터로 만들어줍니다.
- 25088차원의 벡터를 Dropout을 적용하여 4096개의 뉴런과 Fully Connected 해줍니다.
- ReLU 함수로 활성화합니다.
Fifteenth Layer(Fully Connected Layer)
- 이전 단계의 4096개 뉴런과 Dropout을 적용하여 다른 4096개 뉴런으로 fully connected 해줍니다.
- ReLU 함수로 활성화합니다.
Sixteenth Layer(Fully Connected Layer)
- 이전 단계의 4096개 뉴런과 다른 1000개 뉴런으로 fully connected 해줍니다.
- ReLU 함수로 활성화합니다.
- 1000개 뉴런 출력값에 Softmax 함수를 적용하여 1000개 클래스 각각에 속할 확률을 나타냅니다.
출처
[1] VGGNet: https://bskyvision.com/504
[2] VGGNet: https://ctkim.tistory.com/114?category=880317
'University > Vehicle Intelligence Foundation' 카테고리의 다른 글
| [CNN] GoogLeNet (1) | 2021.04.20 |
|---|---|
| [CNN] ResNet18 (0) | 2021.04.19 |
| [CNN] AlexNet (0) | 2021.04.18 |
| [실습] YOLO - Object Detection (0) | 2021.04.07 |
| [Perception Open Source] Point Cloud Library (0) | 2021.04.06 |



